Screaming Frog Log File Analyser avec Rankerfox
Utilisez Screaming Frog Log File Analyser dans le forfait Premium Rankerfox pour importer des logs serveur, vérifier les robots de recherche et d'IA, lire les URL vraiment crawlées, repérer les erreurs, mesurer la fréquence de passage et comparer les logs avec vos données de crawl.
Forfait
Screaming Frog Log File Analyser est rattaché au forfait Premium Rankerfox pour les audits techniques avancés, les migrations et la lecture de logs serveur.
Usage fort
Analyse des robots, URL crawlées, codes de réponse, redirections, temps de réponse, octets, sections visitées et pages non découvertes.
Version publique
La version 7.0 met en avant la vérification des AI bots, les groupes de user-agents, les séries temporelles et des exports plus pratiques.
Voir ce que les robots visitent vraiment
Un crawl montre ce qu'un outil peut découvrir. Les logs montrent ce que Googlebot, Bingbot, les robots d'IA ou d'autres agents ont réellement demandé au serveur. C'est une lecture précieuse quand il faut distinguer une erreur théorique d'un problème qui consomme du budget crawl, ralentit une section ou laisse des pages importantes sans passage.
Glisser des fichiers de logs dans l'interface, les faire reconnaître et travailler sur une base lisible plutôt qu'une masse de lignes serveur.
Distinguer les vrais robots de recherche et d'IA des user-agents imités, puis concentrer l'analyse sur les passages fiables.
Voir quelles URL sont visitées, quand, par quel robot, à quelle fréquence et avec quels codes de réponse.
Isoler 4XX, 5XX, redirections, incohérences de réponse et sections qui reçoivent des passages inutiles.
Utiliser les séries temporelles pour repérer pics de crawl, chutes, lenteurs, changements de codes ou activité robot inhabituelle.
Importer un crawl SEO Spider, un sitemap ou une liste d'URL pour trouver pages orphelines, pages connues mais non visitées et écarts de couverture.
Les vues Log File Analyser à utiliser dans un audit
Les captures publiques de Screaming Frog montrent un outil très concret : on trie les événements, on vérifie les bots, on segmente les familles de robots, puis on rapproche les logs des URL connues.
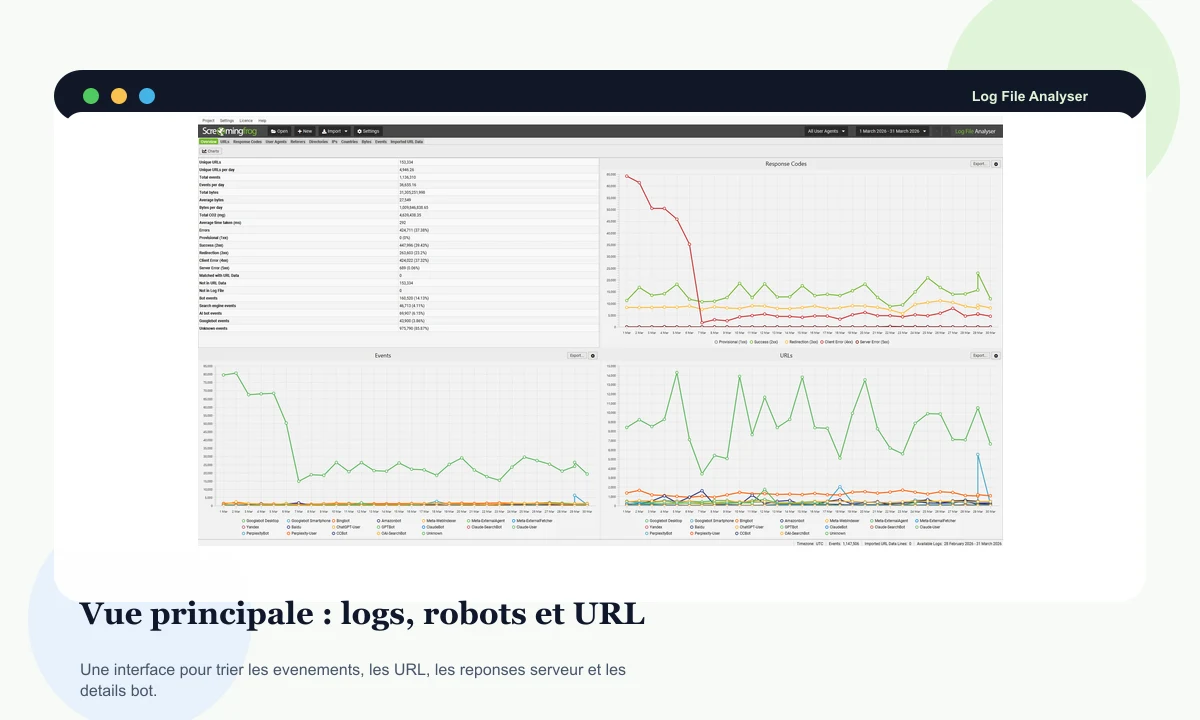
L'interface regroupe événements, URL, codes de réponse, user-agents, graphiques et détails pour passer d'un fichier brut à une lecture SEO exploitable.
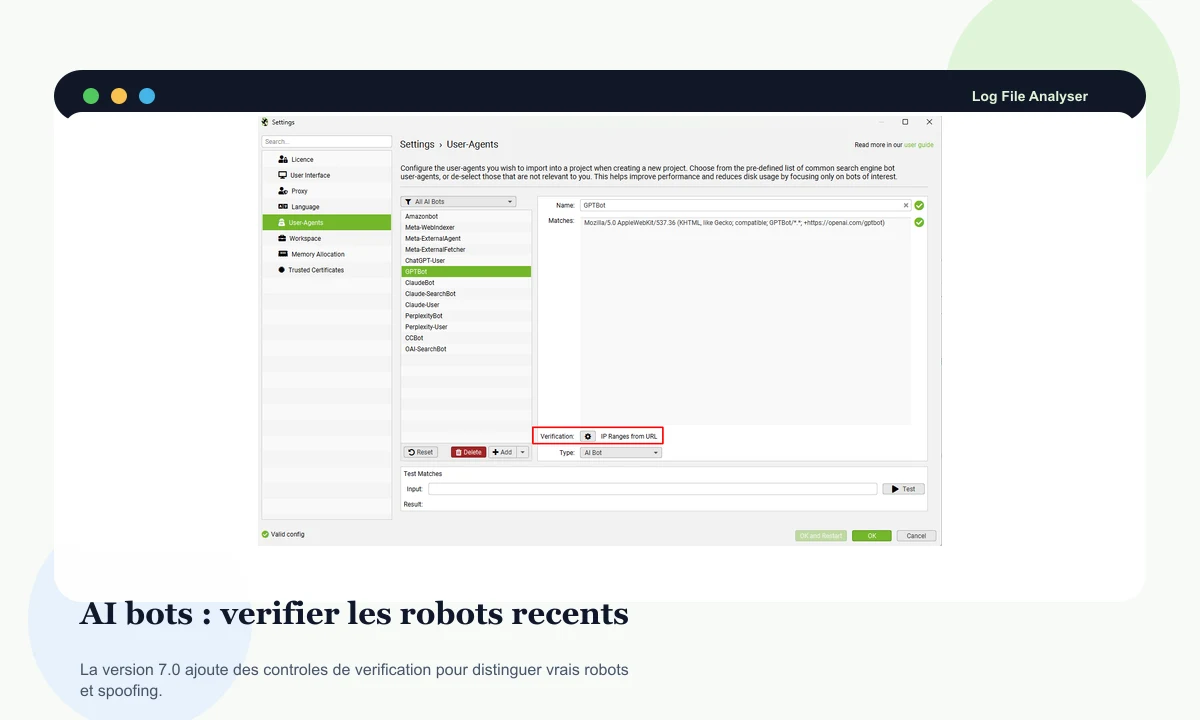
La version 7.0 ajoute la vérification des robots d'IA, utile pour suivre ChatGPT, Perplexity, ClaudeBot ou d'autres agents sans mélanger vrai crawl et imitation.
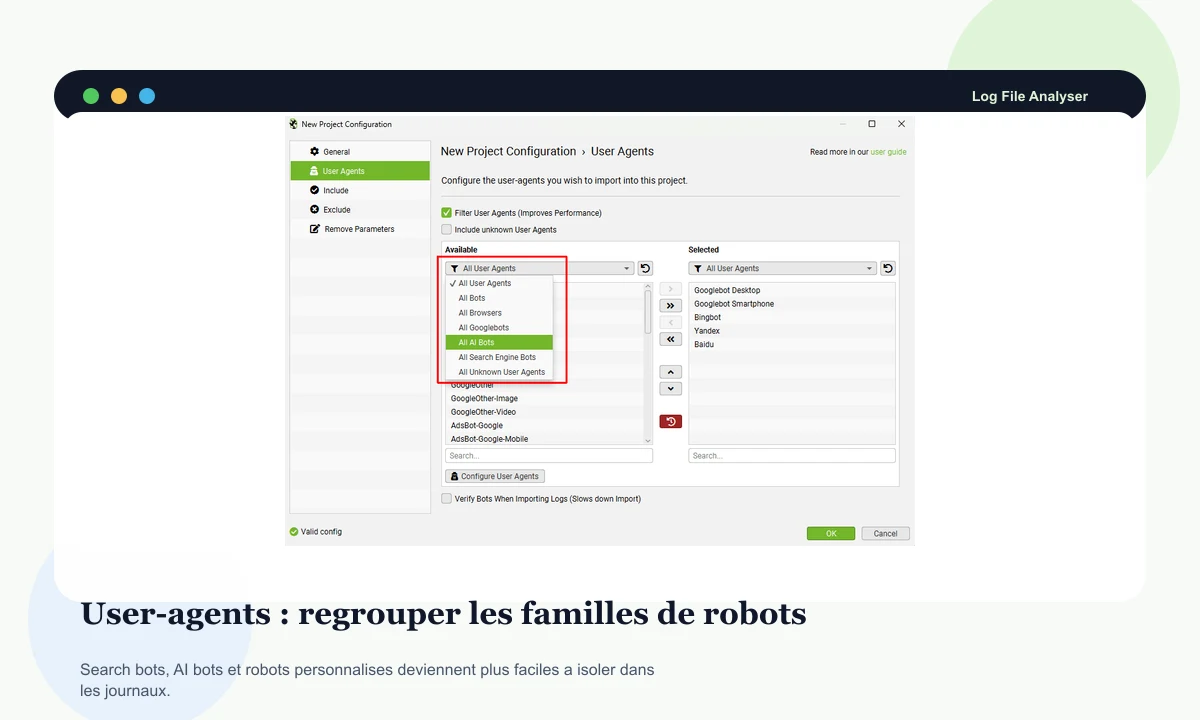
Les groupes permettent d'isoler robots de recherche, robots d'IA, agents personnalisés et autres familles sans bricoler chaque filtre à la main.
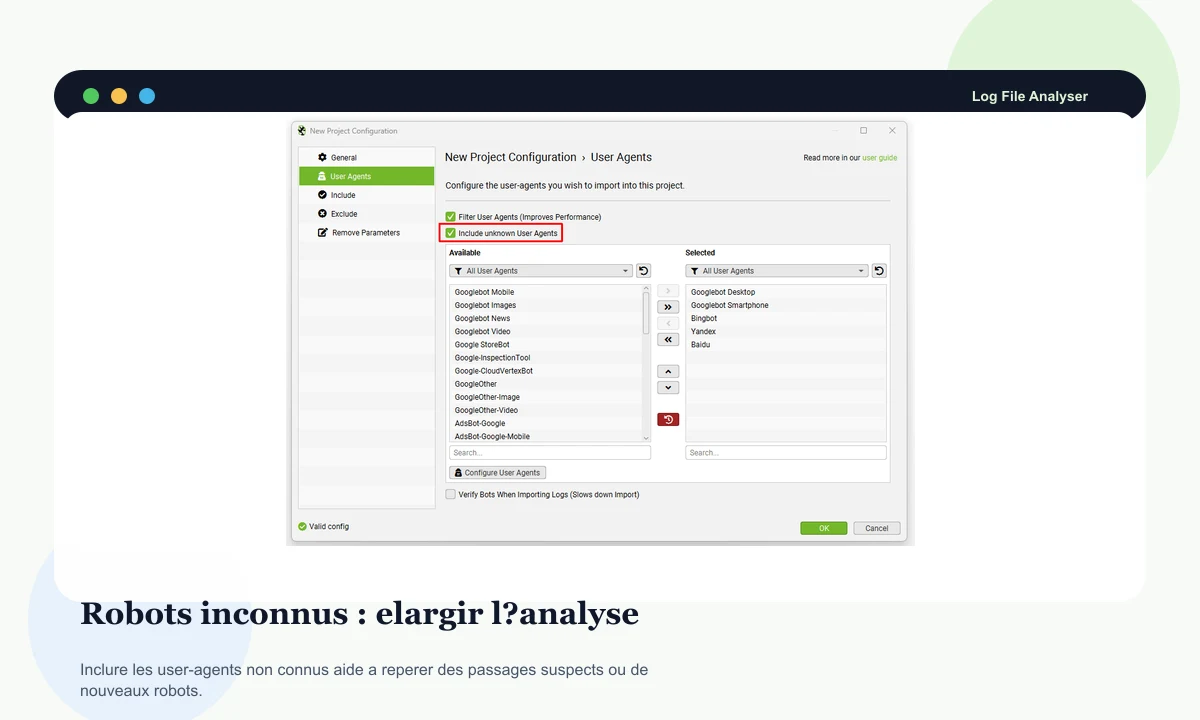
Inclure les agents inconnus peut aider à repérer un robot émergent, un crawler agressif ou une activité à surveiller côté serveur.
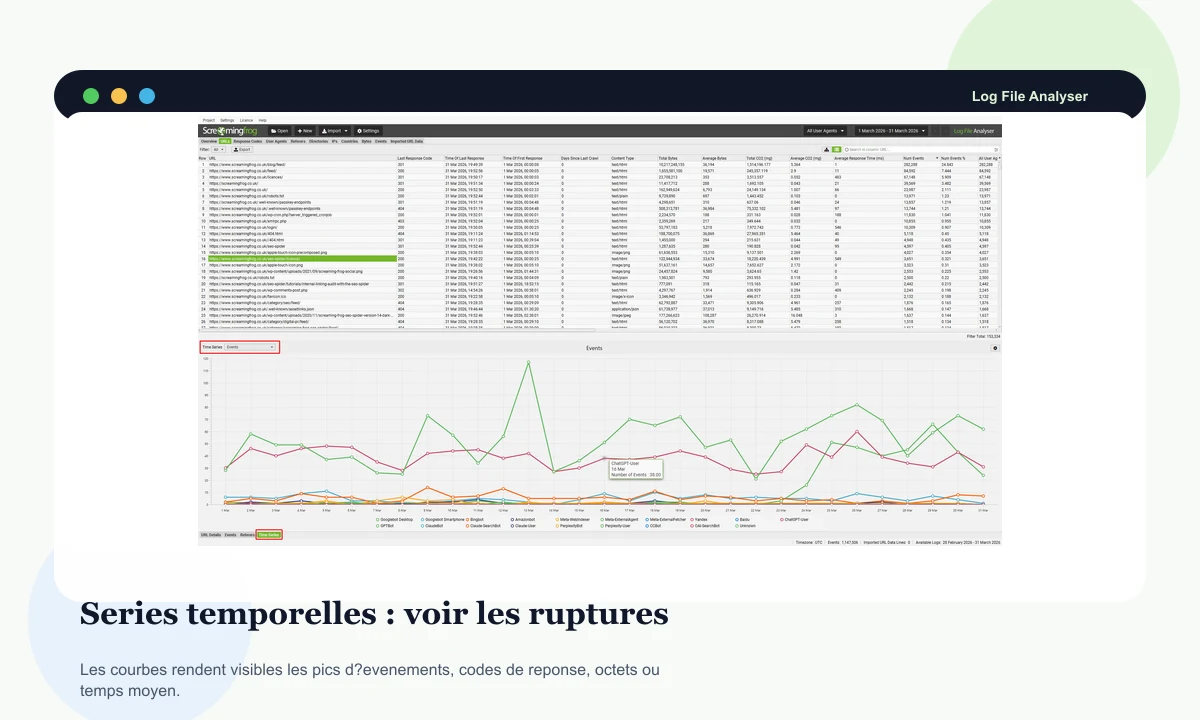
Les graphiques par événements, codes, octets ou temps moyen rendent visibles les ruptures qui se perdent dans un tableau trop long.
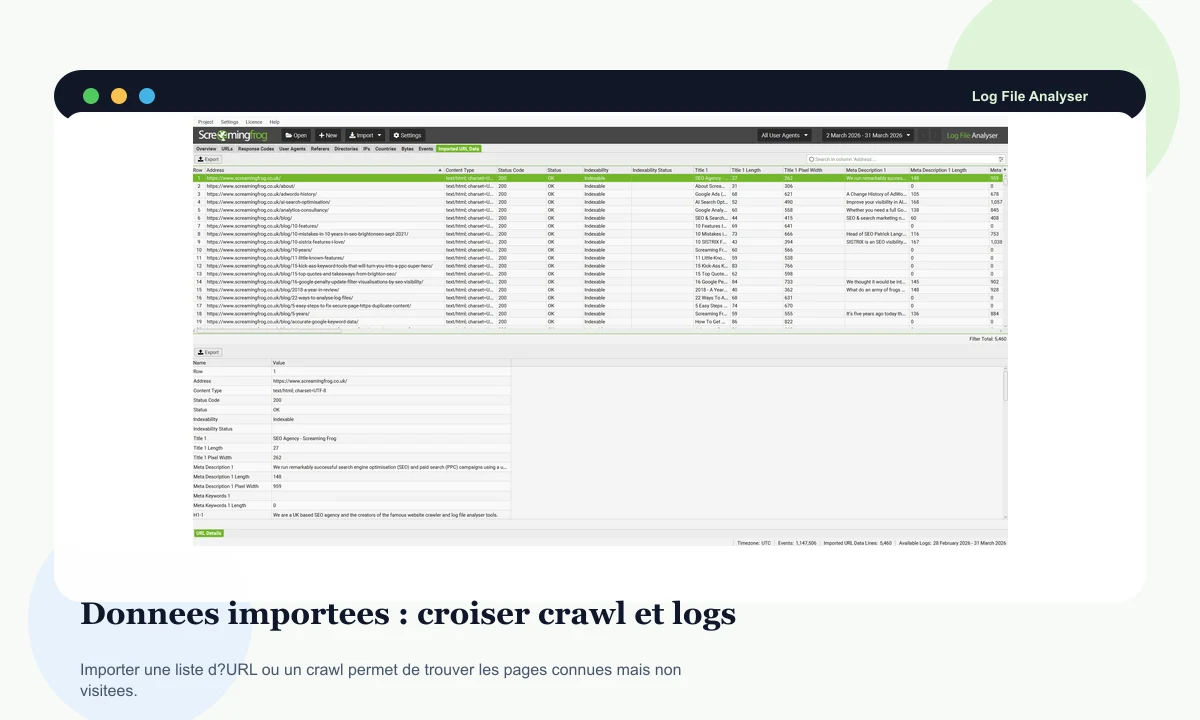
Importer un crawl, un sitemap ou une liste d'URL permet de vérifier si les pages attendues sont réellement vues par les robots.
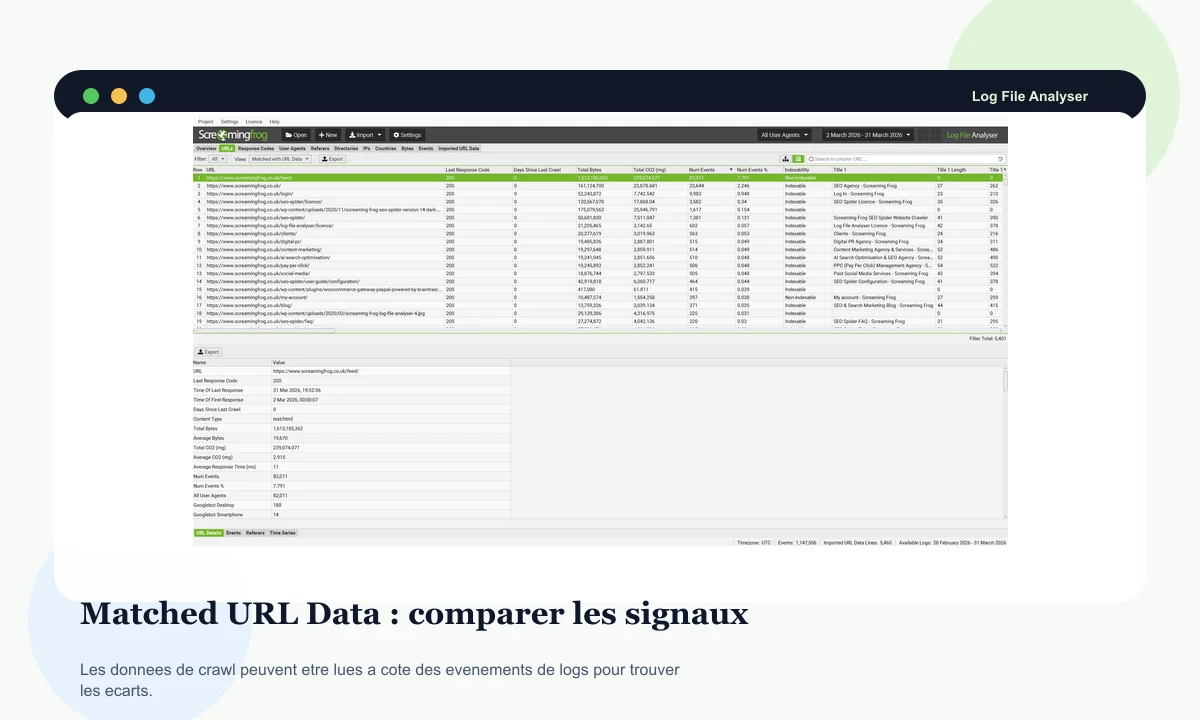
Le rapprochement aide à identifier les URL présentes dans les logs mais absentes du crawl, ou les URL connues que les robots ne visitent pas.
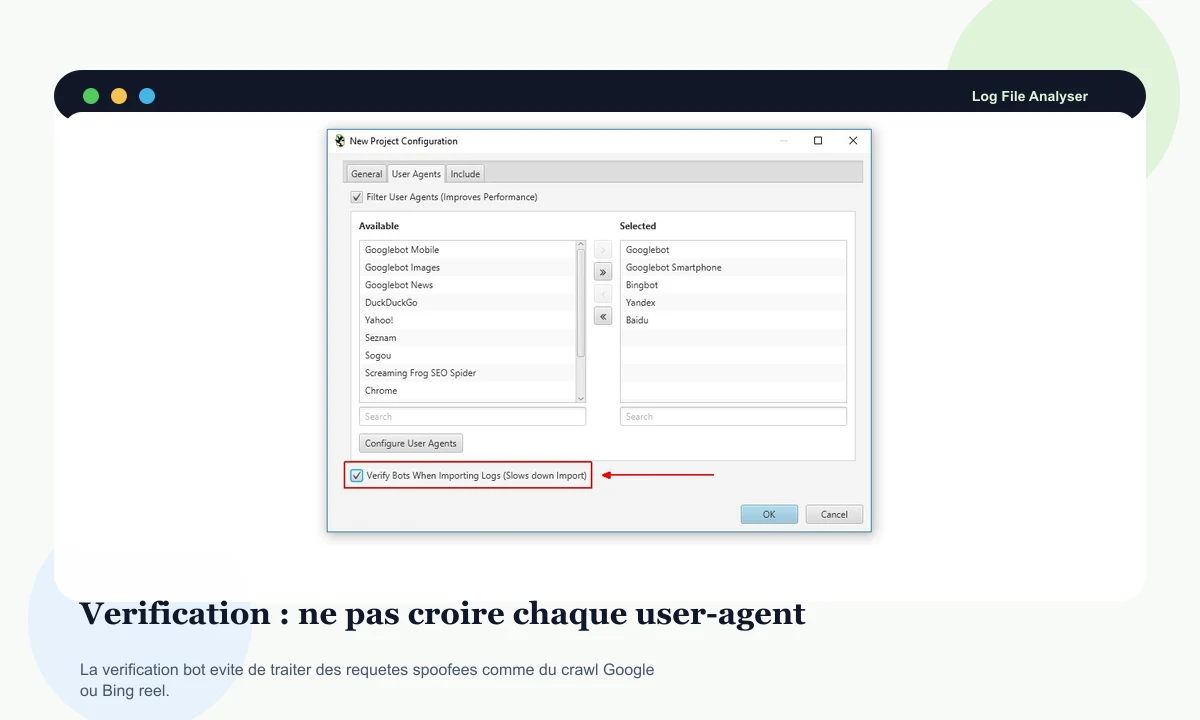
Avant de tirer une conclusion, il faut vérifier que le robot observé correspond bien à un bot légitime et non à une requête déguisée.
Dans quels cas l'utiliser en priorité ?
Le Log File Analyser devient très utile quand une décision dépend du comportement réel des robots. On ne cherche pas seulement des erreurs : on cherche ce qui est visité, ignoré, gaspillé ou ralenti.
Après une migration, les logs indiquent si les robots reviennent sur les anciennes URL, suivent les redirections et découvrent les nouvelles sections.
- Suivre les anciens chemins encore demandés par les robots.
- Repérer les redirections trop fréquentes ou incohérentes.
- Comparer les pages stratégiques avec leur dernier passage robot.
Sur un site volumineux, l'analyse aide à voir si les robots passent du temps sur les bons dossiers ou s'épuisent dans des zones secondaires.
- Lister les sections les plus et les moins crawlées.
- Repérer les paramètres, archives ou pages faibles qui consomment des passages.
- Prioriser les corrections qui rendent le crawl plus utile.
Un outil de crawl peut voir une erreur. Les logs montrent si les robots la rencontrent eux aussi, à quelle fréquence et sur quelles périodes.
- Classer les 4XX, 5XX et redirections par volume d'événements.
- Identifier les réponses instables sur une même URL.
- Relier les pics d'erreurs à une date, un déploiement ou une section.
En croisant crawl, sitemap et logs, on voit les pages connues mais jamais visitées, ainsi que les URL découvertes dans les logs mais absentes du crawl.
- Importer les URL du SEO Spider ou d'un sitemap.
- Comparer les vues Not In Log File et Not In URL Data.
- Décider s'il faut renforcer, corriger, rediriger ou retirer une URL.
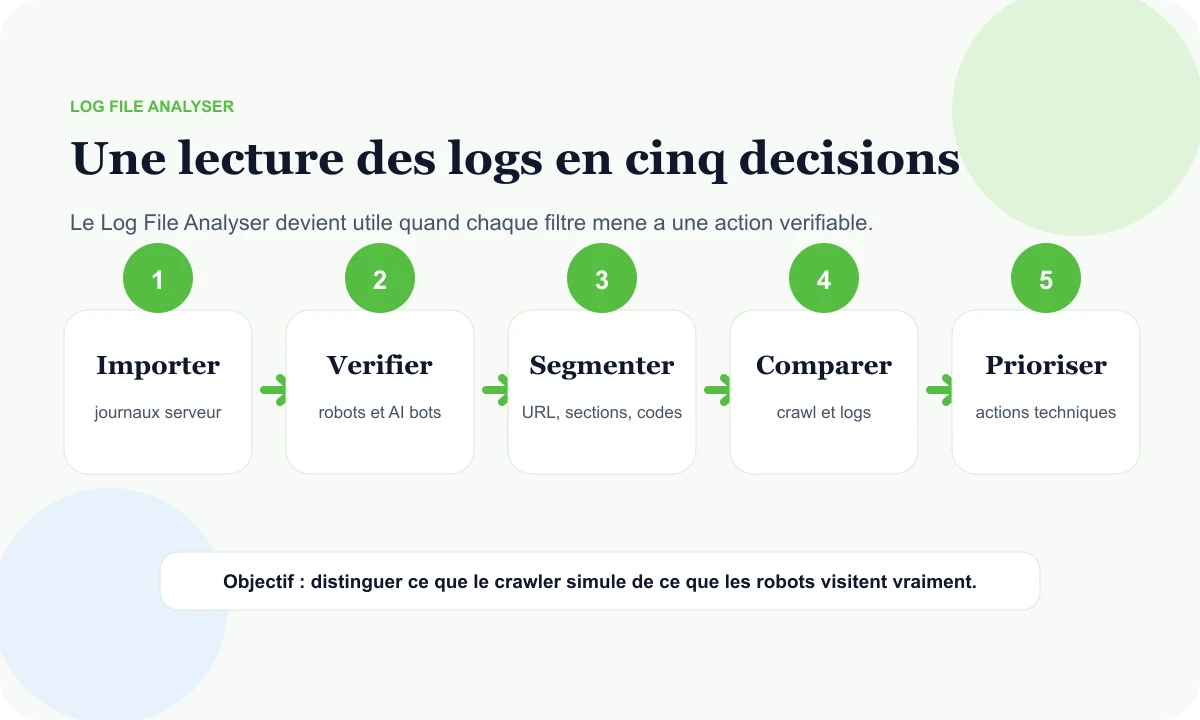
Une routine logs en cinq décisions
Les logs peuvent devenir très bruyants. Une routine simple évite de se perdre : importer, vérifier, segmenter, comparer et prioriser.
Importer
Rassembler les bons journaux serveur sur la bonne période, avec user-agent, date, URL, statut, taille et temps de réponse quand ces données existent.
Vérifier
Contrôler les bots de recherche, les robots d'IA et les agents personnalisés pour ne pas bâtir l'analyse sur du trafic imité.
Segmenter
Découper par robot, répertoire, statut, période, taille, temps de réponse et type d'URL pour voir les zones qui comptent.
Comparer
Importer crawl, sitemap ou liste d'URL, puis rapprocher les pages connues des événements réellement observés.
Prioriser
Transformer les écarts en actions : corriger, rediriger, désindexer, améliorer la structure ou surveiller une section.
Comment le situer avec SEO Spider et les suites SEO
Le Log File Analyser n'a pas le même point de départ qu'une suite de visibilité. Il part des journaux serveur, donc de l'activité réelle observée par le serveur.
SEO Spider simule un crawl et inspecte les URL, balises, directives, JavaScript, sitemaps et données structurées.
Log File Analyser complète ce diagnostic en montrant ce que les robots ont réellement demandé, quand, combien de fois et avec quelles réponses serveur.
DinoRANK aide à relier visibilité, contenu, cannibalisations et priorités plus éditoriales.
Log File Analyser intervient quand la question porte sur les passages robot, l'exploration réelle et les erreurs observées dans les logs.
SEOZoom garde une lecture de suite SEO autour des contenus, concurrents, analyses et rapports.
Log File Analyser apporte une preuve serveur pour arbitrer les problèmes techniques qui ne se voient pas toujours dans une suite générale.
Semrush aide à cadrer marché, concurrents, opportunités et audits généraux.
Les logs servent ensuite à vérifier si les pages importantes reçoivent bien l'attention des robots et si les erreurs sont réellement rencontrées.
Dans quel forfait Rankerfox se trouve Screaming Frog Log File Analyser ?
L'essai sert à découvrir Rankerfox et à vérifier l'environnement. Pour l'analyse de logs avancée, le repère à retenir est le forfait Premium.
Le Standard couvre déjà plusieurs usages SEO quotidiens, mais Screaming Frog Log File Analyser est présenté ici comme un outil Premium.
Screaming Frog Log File Analyser est rattaché au forfait Premium à 14.99€/mois pour les audits logs, robots, migrations et diagnostics techniques avancés.
Continuer avec les pages proches
Crawler le site, lire les statuts, balises, directives, sitemaps, JavaScript et priorités techniques.
Relier analyse, contenu, cannibalisations, suivi et priorités de correction.
Garder une vision de suite SEO autour de la visibilité, des contenus et du reporting.
Comparer les accès SEO inclus dans Rankerfox selon les usages.
Questions fréquentes sur Screaming Frog Log File Analyser
Les points utiles avant d'ajouter l'analyse de logs à une routine SEO technique dans le forfait Premium.
Ajoutez les logs serveur à votre diagnostic SEO
Comparez les forfaits Rankerfox, puis utilisez Log File Analyser avec SEO Spider pour passer d'un crawl simulé à une lecture plus complète du comportement réel des robots.
Comparer les forfaits